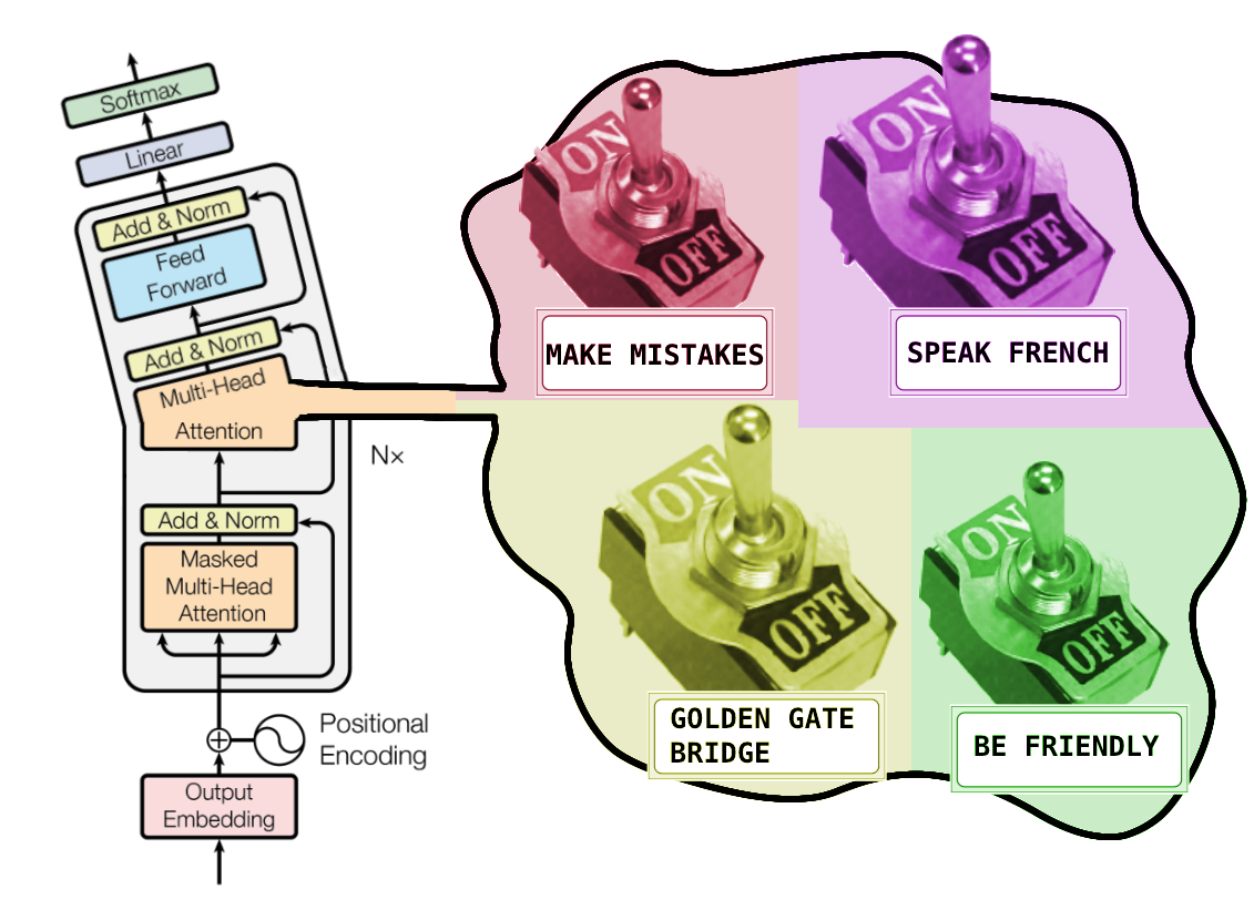
The switch that turns off mistakes
Understanding Anthropic’s “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet” and its implications for controlling models TL;DR Anthropic has shown there are clusters of neurons in LLMs that activate for specific behaviors and contexts. Features like “Coding Errors”, “Golden Gate Bridge”, or “Languages in Cyrillic script”. These are both read and write. When the model produces a coding error the “Coding Errors” cluster lights up. When you force this cluster off… it stops coding errors. This is a path towards controlling and interpreting LLMs - a future exists where models include switches to activate/inhibit different behavior. ...